Over the past year, countless AI video generators, such as Pika, Runway Gen, and various other AI tools, have been launched, and they are performing exceptionally well. Additionally, there is noteworthy news from Google Research regarding the release of their AI video generator, named LUMIERE AI.
This AI model, currently in development, functions as both a text-to-video and image-to-video AI. It leverages a revolutionary “Space-Time U-Net architecture” to generate remarkably fluid and detailed videos based on textual descriptions or reference images.
This article aims to provide a comprehensive breakdown of Google Lumiere AI and showcase the demo videos released by Google Lumiere.
Google Lumiere AI Video Generator
Google Lumiere AI is an innovative artificial intelligence model developed by Google Research. It operates as a text-to-video and image-to-video AI, utilizing a revolutionary “Space-Time U-Net architecture” to generate fluid and detailed videos from textual descriptions or reference images.
Google Lumiere represents has several key features that set it apart:
1. Text-to-video Generation:
LUMIERE enables the creation of high-quality videos based on written prompts, transforming imagination into moving pictures with ease.
2. Image-to-video Animation:
It breathes life into still images, infusing them with context, movement, and stylistic variations for a dynamic visual experience.
3. Advanced Video Editing Capabilities:
The model offers fine-tuning options for specific elements such as lighting, style, and object movement within the generated video, allowing for creative control.
4. Realistic and Consistent Output:
LUMIERE achieves unparalleled fluidity and detail by simultaneously considering spatial and temporal aspects, ensuring a realistic and consistent output.
5. Versatility Beyond Text-to-video:
Its capabilities extend beyond text-to-video, allowing users to generate cinematography, repair damaged footage, and explore interactive video experiences.
Impressive Video Demos
Fascinating demo videos on lumiere-video.github.io showcase the model’s capabilities, offering a glimpse into its ability to generate highly realistic and coherent videos.
The demos highlight its potential in diverse applications, from simple animations to complex cinematic scenes.
Consistency in Video Rendering
A standout feature of LUMIERE is its consistency in video rendering. Unlike traditional models, LUMIERE generates the entire temporal duration of the video in one go, thanks to its unique SpaceTime unit architecture.
This approach efficiently handles both spatial and temporal aspects of the video data, setting it apart from conventional methods.
User Preference and Benchmarking
In user studies, LUMIERE has outperformed other models in both text-to-video and image-to-video generation.
Benchmarks have shown its superiority against competitors like Pika Labs, zeroscope, and Gen 2 (Runway), establishing LUMIERE as the gold standard in text-to-video generation, aligning with predictions that 2024 is poised for significant advancements in this domain.
How to Access Google LUMIERE AI Video Generator?
While Google Lumiere is currently in the research and development phase and not available for public use, insights from Google AI research suggest potential usage scenarios:
Text Prompts: Provide simple text descriptions of a scene, event, or character, and Lumiere could generate a video based on the provided words.
Reference Images: Users could potentially upload an image as a starting point, and Lumiere would animate it, create variations, or generate a video scene inspired by it.
Google LUMIERE Architecture
The architectural innovations that make LUMIERE a standout model in text-to-video generation include:
SpaceTime Unit Architecture: Departing from traditional models, LUMIERE generates the entire video’s temporal duration in a single pass, resulting in more coherent and realistic motion.
Temporal Downsampling and Upsampling: Incorporating both spatial and temporal downsampling and upsampling enhances the model’s ability to process and generate full-frame-rate videos effectively.
Using Pre-trained Texture Image Diffusion Models: LUMIERE builds upon text-to-image diffusion models, adapting them for video generation, combining the strengths of pre-trained models with the complexities of video data.
Addressing Challenges in Video Generation: LUMIERE tackles challenges in maintaining global temporal consistency, ensuring that generated videos exhibit coherent and realistic motion throughout their duration.
Exploring LUMIERE’s GitHub Page
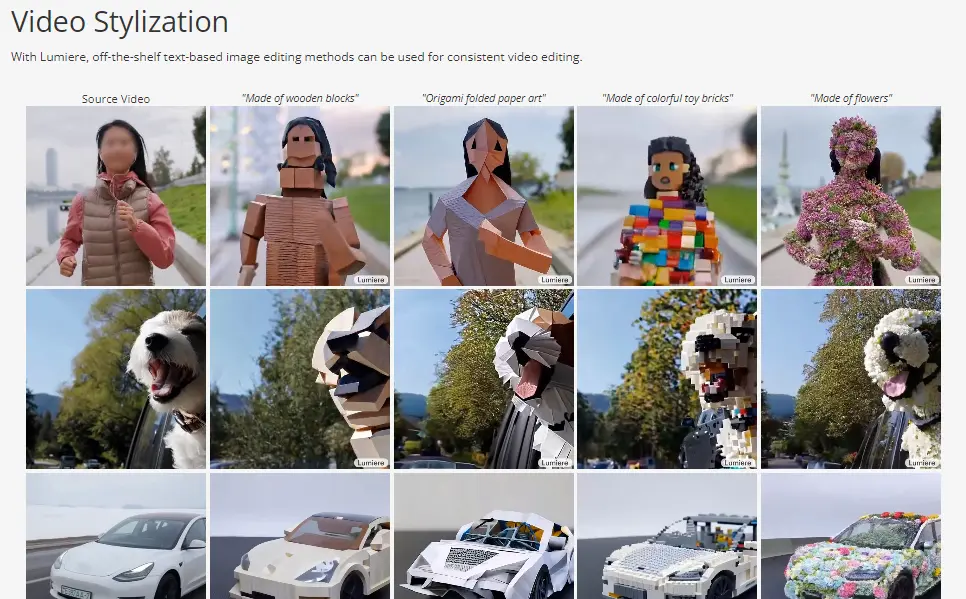
A visit to LUMIERE’s GitHub page provides deeper insights into its capabilities. LUMIERE excels not only in text-to-video generation but also in stylized video production.
Its ability to apply various styles to videos, as demonstrated with references to the Style Drop paper, showcases its versatility.
Stylized videos imitating 3D animation or mimicking famous paintings highlight the model’s potential in creative applications.
Conclusion
The article concludes with speculation about Google’s plans for LUMIERE, pondering whether it will be released as a standalone product or incorporated into a larger project.
The model’s potential for widespread use and its competitive edge in the text-to-video domain raise questions about its future trajectory.
For those interested in the in-depth technical details, the official LUMIERE AI paper provides a comprehensive read. As we await further developments, Google Lumiere stands as a beacon of innovation, paving the way for a new era in AI-driven video generation.